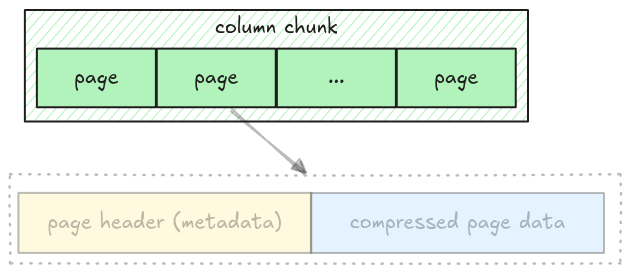
Data Pages
As noted in the Understand File Format, a column has multiple pages, all packed together. In this step, we will extract all pages for a given column chunk.
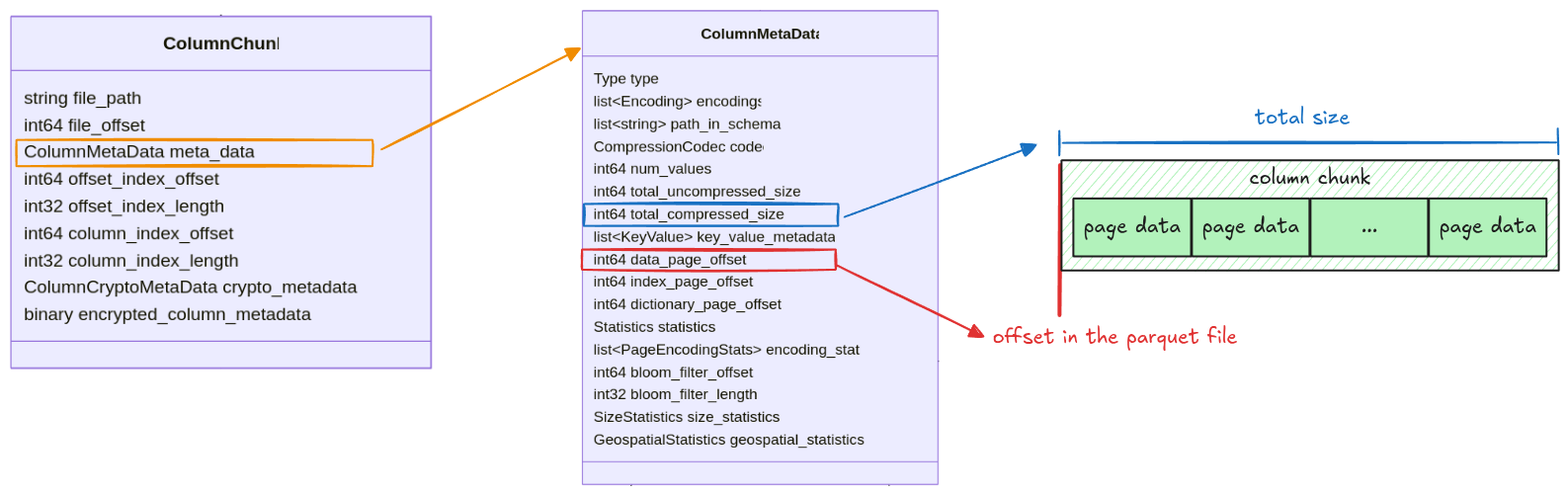
All information for getting a column chunk data is stored in the ColumnMetaData, which contains:
data_page_offset: the offset of a column chunk in a parquet filetotal_compressed_size: the length of a column chunk data, this includes multiple pages packed together
Pages in a column chunk are represented as Pages struct with 2 fields: data_pages and
dictionary_page. For this step, we only focus on the data_pages, the dictionary_page will be
handled later in the Dictionary Page section.
pub struct Pages {
pub data_pages: Vec<Page>,
pub dictionary_page: Option<Page>,
}Task
Implement the read_pages function in src/page.rs. It takes the entire file data as Bytes and
returns a Pages struct.
pub fn read_pages(data: Bytes, column_metadata: &ColumnMetaData) -> Result<Pages> {
todo!("step04: read all pages for a given column chunk")
}You should use the read_page function from the previous step and keep
extracting pages until there are none left.
Test
Test case for this step is step04_data_pages.
Hints and Solution
Hint (how to get the raw column chunk bytes)
The column chunk’s position and its length are stored in data_page_offset and
total_compressed_size. The raw bytes can be extracted like this:
let column_chunk_data = data.slice(data_page_offset..data_page_offset + total_compressed_size)Hint (how to extract all pages)
The read_page function returns the remaining bytes. Keep applying read_page until there are no
bytes left.
while !data.is_empty() {
let (page, remaining) = read_page(/* ... */);
data = remaining;
}Solution
pub fn read_pages(data: Bytes, column_metadata: &ColumnMetaData) -> Result<Pages> {
let offset = column_metadata.data_page_offset as usize;
let len = column_metadata.total_compressed_size as usize;
let mut pages_bytes = data.slice(offset..offset + len);
let mut data_pages = vec![];
while !pages_bytes.is_empty() {
let (page, remaining) = read_page(pages_bytes, column_metadata.codec)?;
data_pages.push(page);
pages_bytes = remaining;
}
Ok(Pages {
data_pages,
dictionary_page: None,
})
}