Overview
This section describes a high-level overview of parquet and what we will do (roughly) to parse it.
Parquet File Format
Parquet is a columnar file format; unlike traditional row-based formats, parquet stores column data close together.
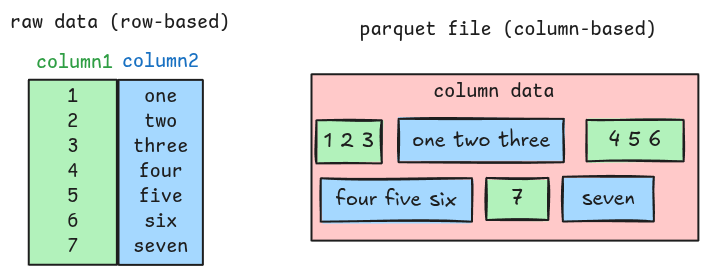
Along with the actual column data, a parquet file also contains metadata such as column position, column type, encoding, etc. These provide enough information to the parser for extracting all the column data. This means the parser must understand both the metadata and the column data to completely parse a parquet file.
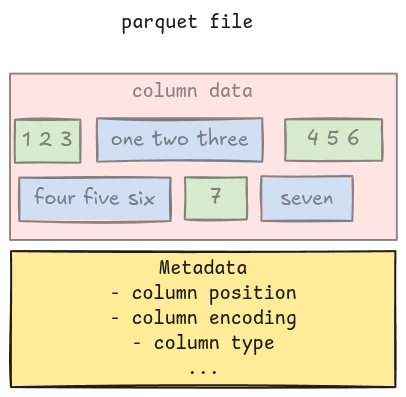
Metadata
In parquet, metadata includes file metadata, column metadata, row group metadata, column chunk metadata, etc. There are many of them, and writing a parser to parse them is a daunting task. Luckily, the spec comes with a full Thrift definition for all the metadata, which can be used to generate all parsing code.
The starter code includes a ready-to-use function for this: read_thrift_metadata, which takes a
Bytes, and returns a corresponding metadata with the remaining bytes, based on the template
argument.
let (metadata, remaining) = read_thrift_metadata::<MetaData>(data);Column data
The main focus in the book will be parsing column data. The flow can be simplified like this:
- Read the metadata
- Parse the column data
- Merge all the column data together
Implementation
The book has several sections building on top of each other. Below is a rough guideline:
- Parse the file metadata
- Parse a single column with Plain Encoding
- Parse many columns
- Parse a complete file
- Parse files with RLE Bit-packing Hybrid Encoding
- Parse files with null values
- Parse files with Dictionary Encoding
- Parse files with compression