Top down operator precedence parsing
Top down operator precedence (TDOP) is a simple yet powerful algorithm for parsing arithmetic expressions. It is applied in rust analyzer, and the Zig parser appears to use it as well.
In this post, I’ll implement a TDOP
parser for a toy expression programming language (1 + 2 * (3 + 4) - 5).
I’ll try to keep it simple such that no background on parsing
is required.
Background
The purpose of a parser is to transform a stream of tokens
into a parse tree. It inspects each token
and predicts which expression should be used,
for example, when a parser sees print, it knows the
expression might be print(<something>), and applies
that pattern to create a parse tree.
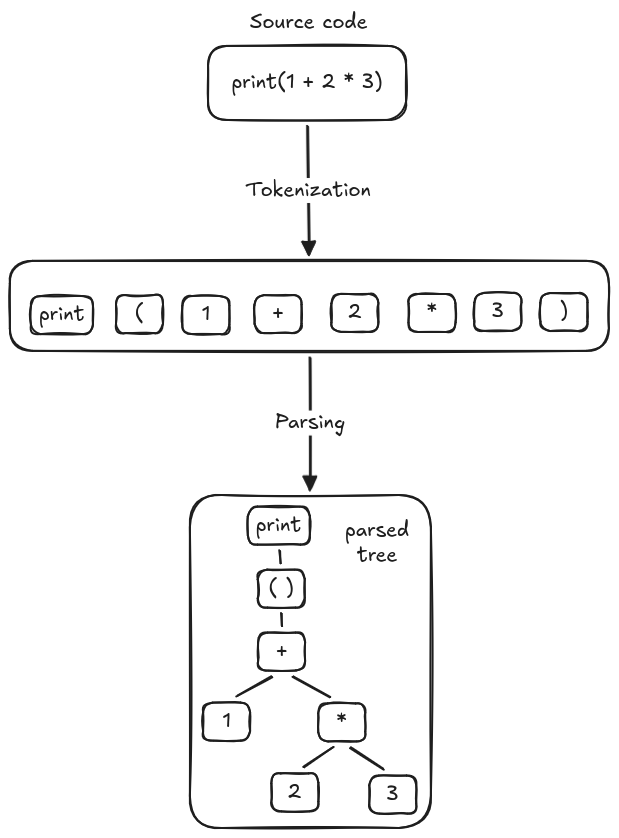
We can parse print("Hello World") like this, just walk straight
from left to right, consuming tokens as we move forward.
const TOKENS: [&'static str; 4] = [
"print", "(", r#""Hello World""#, ")"
];
fn parse_print(tokenizer: &mut Tokenizer) -> PrintExpr {
expect_token(tokenizer, "print");
expect_token(tokenizer, "(");
let string = tokenizer.next().unwrap();
expect_token(tokenizer, ")");
PrintExpr(string.to_string())
}However, this doesn’t play well with arithmetic expressions, there are two main reasons.
Associativity problem
When a parser sees 2 in 1 + 2 * 3, it must determine which operator 2 is associated with.
From our perspective, we know it must be *, which gives us this tree.
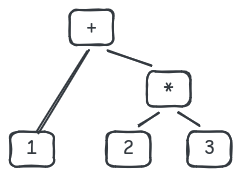
But our parser doesn’t know about this, it sees + and * as simply tokens.
and since it consumes tokens left-to-right, it hasn’t seen * yet when it reaches 2.

Prefix and infix operators problem
In arithmetic expressions, tokens have
different meanings based on their position.
For example, - can be interpreted as:
- Minus operator (prefix operator) in
-1. - Subtraction operator (infix operator) in
1 - 2.
The parser must distinguish which operator to apply based on the context, not from the token itself.
TDOP parser
The TDOP parser overcomes the above challenges by
treating operators as first class, i.e.
it sees - in -1 and 1 - 2 differently.
Let’s implement one to see how it can be done.
Boilerplate
Tokenizer
The parser needs to consume tokens somewhere, we create a tokenizer for that purpose. It helps us transform source code into a stream of tokens, which our parser can use.
Our toy programming language consists of
numbers, +, -, *, and parentheses,
we define an enum Token to represent them.
#[derive(Debug, Copy, Clone)]
enum Token {
Number(u32),
Add,
Sub,
Mul,
LParen,
RParen,
}We don’t need a perfect tokenizer (our goal isn’t writing one anyway),
just a simple regex that can parse all of the
above tokens is enough: [0-9]+|[+\-*()].
It also needs to support querying the next token (next method)
and looking ahead without consuming (peek method),
we use Peekable<Iterator>
to accommodate that.
use regex::Regex;
type Tokenizer = std::iter::Peekable<std::vec::IntoIter<Token>>;
fn tokenizer(program: &str) -> Tokenizer {
let re = Regex::new(r"[0-9]+|[+\-*()]").unwrap();
let tokens: Vec<Token> = re
.find_iter(program)
.map(|m| match m.as_str() {
"+" => Token::Add,
"-" => Token::Sub,
"*" => Token::Mul,
"(" => Token::LParen,
")" => Token::RParen,
s => match s.parse::<u32>() {
Ok(value) => Token::Number(value),
Err(_) => panic!("bad token {}", s),
},
})
.collect();
tokens.into_iter().peekable()
}Given an expression (3 + 4), the tokenizer produces this stream:
LParen, Number(3), Add, Number(4), RParenExpressions
We have the parser’s input - which are tokens. But what about its output - the parse tree? Recall from the tree earlier, its leaf nodes are just literal numbers, while its internal nodes are expressions.
To represent this tree, an enum with different types of nodes is a perfect fit.
use std::fmt;
enum Expr {
Literal(u32),
BinaryAdd { lhs: Box<Expr>, rhs: Box<Expr> }, // lhs + rhs
BinarySub { lhs: Box<Expr>, rhs: Box<Expr> }, // lhs - rhs
BinaryMul { lhs: Box<Expr>, rhs: Box<Expr> }, // lhs * rhs
}To debug the parse tree, our expressions need to be printable and evaluable.
-
For printing, we implement
Displayusing Polish Notation.impl fmt::Display for Expr { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { match self { Expr::Literal(value) => write!(f, "{}", value), Expr::BinaryAdd { lhs, rhs } => write!(f, "(+ {lhs} {rhs})"), Expr::BinarySub { lhs, rhs } => write!(f, "(- {lhs} {rhs})"), Expr::BinaryMul { lhs, rhs } => write!(f, "(* {lhs} {rhs})"), } } } -
For evaluating, a simple recursive walk should work just fine.
fn eval(expr: &Expr) -> i64 { match expr { Expr::Literal(value) => *value as i64, Expr::BinaryAdd { lhs, rhs } => eval(lhs) + eval(rhs), Expr::BinarySub { lhs, rhs } => eval(lhs) - eval(rhs), Expr::BinaryMul { lhs, rhs } => eval(lhs) * eval(rhs), } }
The parse tree for 1 + (2 * 3), we can see that:
-
Parse tree:
BinaryAdd { lhs: Literal(1), rhs: BinaryMul { lhs: Literal(2), rhs: Literal(3), }, } -
Polish notation:
(+ 1 (* 2 3)) -
Evaluation:
7
Parser entrypoint
Our parser needs an entry point, where it receives source code and produces the parse tree. This is where we implement the TDOP algorithm.
fn parse(program: &str) -> Expr {
let mut tokenizer = tokenizer(program);
expr(&mut tokenizer)
}
fn expr(tokenizer: &mut Tokenizer) -> Expr {
todo!()
}We also add some utility for testing.
mod test {
use super::*;
fn test_parse(program: &str, expected_display: &str, expected_eval: i64) {
let expr = parse(program);
assert_eq!(expr.to_string(), expected_display);
assert_eq!(eval(&expr), expected_eval);
}
// Testcases go here
}The boilerplate is done, let’s start implementing our parser.
Literal expression
We begin with the easiest one: literal numbers with no operators.
This is simple, just get the next token from the tokenizer
and wrap it as Expr::Literal.
fn literal(tokenizer: &mut Tokenizer) -> Expr {
match tokenizer.next() {
Some(Token::Number(value)) => Expr::Literal(value),
token => panic!("bad token {:?}", token),
}
}We also update expr and add a testcase.
fn expr(tokenizer: &mut Tokenizer) -> Expr {
literal(tokenizer)
}
mod test {
// ...
#[test]
fn literal() {
test_parse("123", "123", 123)
}
}running 1 test
test literal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00sBinary expressions
Next, we handle binary expressions: lhs <op> rhs.
Below is our template, we need to determine how to get lhs, <op>, and rhs.
fn binary(...) -> Expr {
let lhs = todo!("how to get lhs");
let op = todo!("how to get op");
let rhs = todo!("how to get rhs");
match op {
Token::Add => Expr::BinaryAdd { lhs: Box::new(lhs), rhs: Box::new(rhs) },
Token::Sub => Expr::BinarySub { lhs: Box::new(lhs), rhs: Box::new(rhs) },
Token::Mul => Expr::BinaryMul { lhs: Box::new(lhs), rhs: Box::new(rhs) },
_ => panic!("bad op {:?}", op),
}
}Our implementation might be different depending on how many tokens
we have consumed. Let’s look at different options based on
the tokenizer position (represented as |).
-
lhs <op> rhs |: everything has been consumed, ourbinaryis just a no-brainer wrapper aroundExpr::Binary. This isn’t a very helpful option.fn binary(lhs: Expr, op: Token, rhs: Expr) -> Expr { match op { // ... } -
lhs <op> | rhs:lhsand<op>have been consumed, we need to parserhs, this can be done usingexpr.fn binary(tokenizer: &mut Tokenizer, lhs: Expr, op: Token) -> Expr { let rhs = expr(tokenizer); match op { // ... } -
lhs | <op> rhs: we need to parse both<op>andrhs.fn binary(tokenizer: &mut Tokenizer, lhs: Expr) -> Expr { let op = tokenizer.next().unwrap(); let rhs = expr(tokenizer); match op { // ... } -
| lhs <op> rhs: Nothing has been consumed, this is similar to literal expression, we have to parse everything.<op>andrhsare the easy ones, the question is how do we parselhs? Usingexprhere would lead to an infinite recursion; usingliteralwould forcelhsto always beExpr::Literal, which might not be true in all case.
The second and third options are viable options for us.
We go with the third one (lhs | <op> rhs),
this forces binary to do as much as it can,
abstracting away <op> parsing from the caller.
fn binary(tokenizer: &mut Tokenizer, lhs: Expr) -> Expr {
let op = tokenizer.next().expect("missing op for binary expression");
let rhs = expr(tokenizer);
match op {
Token::Add => Expr::BinaryAdd { lhs: Box::new(lhs), rhs: Box::new(rhs) },
Token::Sub => Expr::BinarySub { lhs: Box::new(lhs), rhs: Box::new(rhs) },
Token::Mul => Expr::BinaryMul { lhs: Box::new(lhs), rhs: Box::new(rhs) },
_ => panic!("bad op {:?}", op),
}
}We modify expr to apply new binary function.
It first parses lhs with literal,
then the remaining tokens with binary if there are any.
fn expr(tokenizer: &mut Tokenizer) -> Expr {
let lhs = literal(tokenizer);
if tokenizer.peek().is_none() {
return lhs;
};
binary(tokenizer, lhs)
}Let’s have some new testcases.
#[test]
fn binary_add() {
test_parse("1 + 2", "(+ 1 2)", 3)
}
#[test]
fn binary_sub() {
test_parse("1 - 2", "(- 1 2)", -1)
}
#[test]
fn binary_mul() {
test_parse("2 * 3", "(* 2 3)", 6)
}running 4 tests
test test::literal ... ok
test test::binary_add ... ok
test test::binary_sub ... ok
test test::binary_mul ... ok
test result: ok. 4 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.01sOperator precedence
There is an issue with the current implementation:
the parser always produces a right-deep tree, causing
the associativity problem.
For example, it parses 1 + 2 * 3 + 4 as (+ 1 (* 2 (+ 3 4))),
which is incorrect because 3 + 4 is calculated before 2 * 3.
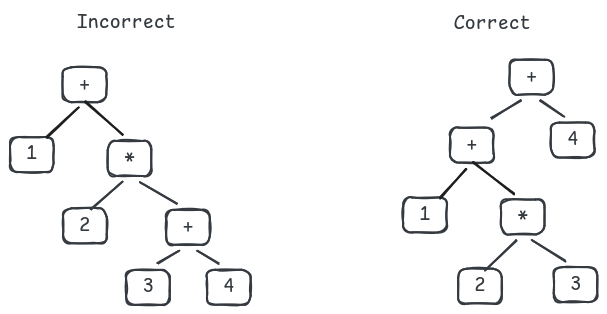
To solve this, the TDOP parser assigns each operator a
binding power, and associates expressions
with operator having higher power.
Take the above example: if we assign + and *
binding powers of 10 and 20,
then 3 must associate with *.

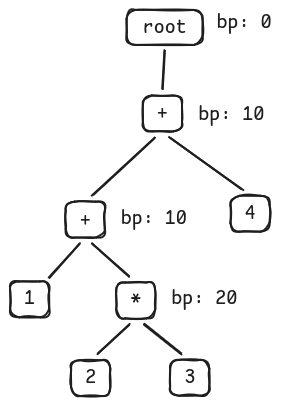
The correct tree with binding power assigned to each operator should be:
Building a correct tree
Look at the tree above, we can see that the child nodes always have higher binding power than the parent nodes. Why is that? Because expressions with higher binding powers must always be computed first. In other words, they are binded tightly together to the lower part of the tree.
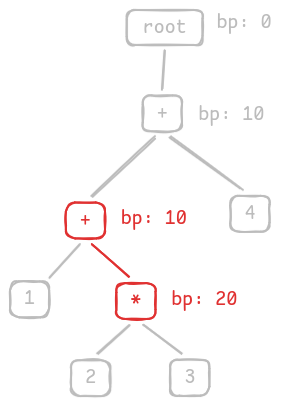
Using this observation, the idea to build a tree is simple:
- If we encounter an operator with a higher binding power than the current node, attach it as a child.
- Otherwise, find an ancestor with a lower binding power and attach it there.
Let’s illustrate this idea by building the parse tree step-by-step.
-
At the beginning, there is only one root node with binding power
0.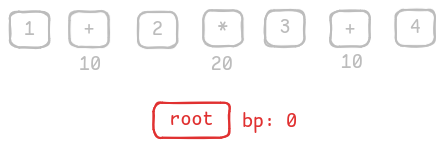
There is only one root node with bp = 0 -
Consume the first 2 tokens. Associate
1with+, move to+right subtree.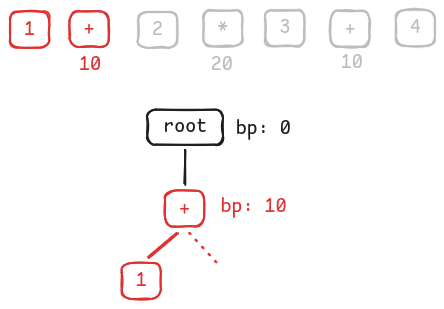
Associate 1 with +'s left and move to +'s right -
Consume the next 2 tokens. Associate
2with*(because*has higher binding power than+), move to*right subtree.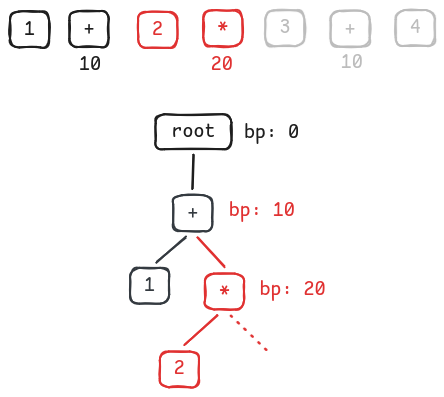
Associate 2 with *'s left and move to *'s right -
Consume the next 2 tokens. Associate
3with*(because*has higher binding power than+).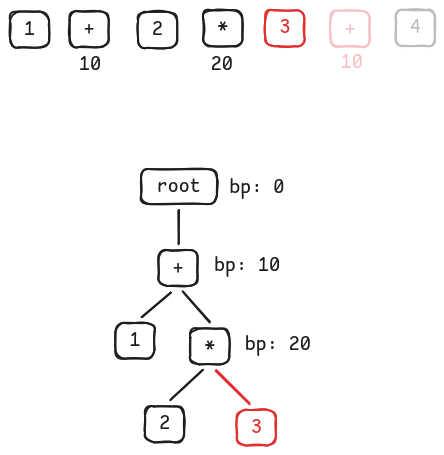
Associate 3 with *'s right -
What about
+? We walk back the tree, find the ancestor with lower binding power - which is the root node, create a new child there, then move to its right.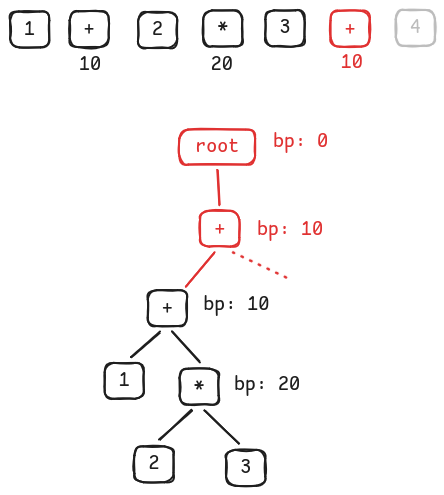
Replace root child with +'s left -
Consume the last token, since there is no other operator, associate it with
+.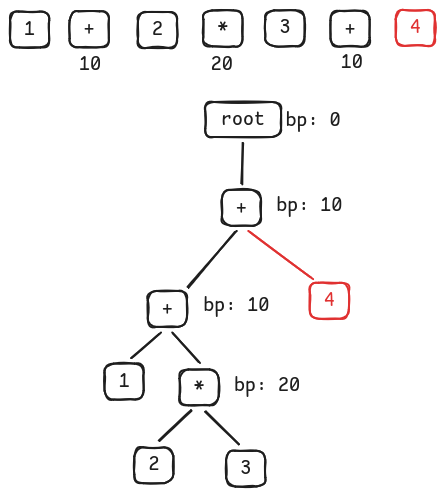
Associate 4 to +'s right
Implement operator precedence
Okay, now we can apply the binding power idea to our parser.
Let’s assign 10 to +, -, and 20 to *.
#[derive(PartialEq, Eq, PartialOrd, Ord)]
struct BindingPower(pub u8);
fn binding_power(token: &Token) -> BindingPower {
match token {
Token::Add | Token::Sub => BindingPower(10),
Token::Mul => BindingPower(20),
_ => panic!("unsupported binding power for {:?}", token),
}
}Our expr should accept power, indicating the current node’s binding power.
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
// ...
}If an operator’s binding power is higher than the current one, descend to the right subtree, otherwise, return the current node to the caller.
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
let lhs = literal(tokenizer);
let Some(op) = tokenizer.peek() else {
return lhs;
};
let bp = binding_power(op);
if bp <= min_power {
return lhs;
}
binary(tokenizer, lhs, bp)
}At the beginning, the binding power should be 0,
representing the root’s binding power. This also means
we parse all operators having binding power higher than 0.
fn parse(program: &str) -> Expr {
let mut tokenizer = tokenizer(program);
expr(&mut tokenizer, BindingPower(0))
}Add new tests, one of them fails unfortunately.
#[test]
fn binary_mul_add() {
test_parse("2 * 3 + 4", "(+ (* 2 3) 4)", 10)
}
#[test]
fn binary_add_mul() {
test_parse("2 + 3 * 4", "(+ 2 (* 3 4))", 14)
}thread 'test::binary_mul_add' (42) panicked at src/main.rs:112:5:
assertion `left == right` failed
left: "(* 2 3)"
right: "(+ (* 2 3) 4)"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtraceLook at the error: 2 * 3 + 4 is parsed as (* 2 3),
this is because we return too early without exploring all
operators with higher binding power.
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
let lhs = literal(tokenizer);
let Some(op) = tokenizer.peek() else {
return lhs;
};
let bp = binding_power(op);
if bp <= min_power {
return lhs;
}
binary(tokenizer, lhs, bp)
}We solve this by adding a loop, iterating through all possible operators.
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
let mut lhs = literal(tokenizer);
loop {
let Some(op) = tokenizer.peek() else {
break;
};
let bp = binding_power(op);
if bp <= min_power {
break;
}
lhs = binary(tokenizer, lhs, bp)
}
lhs
}Because the accepted operator must have higher binding power,
they should take lhs as their left-hand side and produce
a Expr::Binary node.
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
let mut lhs = literal(tokenizer);
loop {
let Some(op) = tokenizer.peek() else {
break;
};
let bp = binding_power(op);
if bp <= min_power {
break;
}
lhs = binary(tokenizer, lhs, bp)
}
lhs
}The testcases should pass.
running 6 tests
test test::binary_add ... ok
test test::binary_add_mul ... ok
test test::binary_mul_add ... ok
test test::binary_mul ... ok
test test::binary_sub ... ok
test test::literal ... ok
test result: ok. 6 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.03sPrefix and infix operators
There is one more issue with our parser: prefix and infix operators problem, let’s fix that.
Apply prefix and infix terminology
We have some observations with prefix and infix forms:
- Prefix operators only require the right hand side:
<op> rhs. - Infix operators need both:
lhs <op> rhs.
But this is exactly what we have done. Literal expression has prefix form (with no prefix operator), and binary expression has (obviously) infix form. We can migrate them to use the new terminology.
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
let mut lhs = literal(tokenizer);
let mut lhs = prefix(tokenizer);
// ...
lhs = binary(tokenizer, lhs, bp);
lhs = infix(tokenizer, lhs, bp);
// ...
}
fn literal(tokenizer: &mut Tokenizer) -> Expr {
fn prefix(tokenizer: &mut Tokenizer) -> Expr {
// ...
}
fn binary(tokenizer: &mut Tokenizer, lhs: Expr, min_power: BindingPower) -> Expr {
fn infix(tokenizer: &mut Tokenizer, lhs: Expr, min_power: BindingPower) -> Expr {
// ...
}Minus expression
As mentioned earlier, TDOP parser treats operators as first class, which means we must handle the prefix form and the infix form of a token separately.
This is what we will do with the - token. Since its infix form
has already been implemented in Expr::BinarySub, we only consider
its prefix form. Let’s add a new Expr::Minus (with the form - <inner>)
for that.
enum Expr {
// ...
Minus(Box<Expr>),
}
impl fmt::Display for Expr {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
match self {
// ...
Expr::Minus(expr) => write!(f, "-{expr}"),
}
}
}
fn eval(expr: &Expr) -> i64 {
match expr {
// ...
Expr::Minus(expr) => -eval(expr),
}
}Because Expr::Minus has prefix form, it should be handled
inside prefix. We call expr to get the inner expression and wrap
it in Expr::Minus.
fn prefix(tokenizer: &mut Tokenizer) -> Expr {
match tokenizer.next() {
Some(Token::Number(value)) => Expr::Literal(value),
Some(Token::Sub) => {
let expr = expr(tokenizer, binding_power(&Token::Sub));
Expr::Minus(Box::new(expr))
}
token => panic!("bad token {:?}", token),
}
}New testcases, and one of them fails.
#[test]
fn prefix_minus() {
test_parse("-2", "-2", -2)
}
#[test]
fn prefix_minus_mul() {
test_parse("-2 * 3", "(* -2 3)", -6)
}thread 'test::prefix_minus_mul' (46) panicked at src/main.rs:122:5:
assertion `left == right` failed
left: "-(* 2 3)"
right: "(* -2 3)"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtraceThe failed test is -2 * 3. Look at its parse tree, 2 * 3 is computed
before -2, meaning * operator binds more tightly than minus (-) operator.
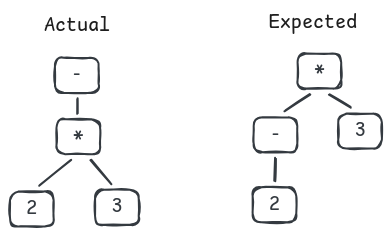
This is because we use the same binding power for both
minus operator and binary sub operator, and all of them
are less than the * operator’s.
fn prefix(tokenizer: &mut Tokenizer) -> Expr {
// ...
Some(Token::Sub) => {
let expr = expr(tokenizer, binding_power(&Token::Sub));
Expr::Minus(Box::new(expr))
}
// ...
}We need to separate binding power for prefix and infix operators.
The binding_power we have been using so far is, in fact,
the binding power for infix operators. Let’s change that.
fn binding_power(token: &Token) -> BindingPower {
fn infix_power(token: &Token) -> BindingPower {
// ...
}
// ...
fn expr(tokenizer: &mut Tokenizer, min_power: BindingPower) -> Expr {
// ...
let bp = binding_power(op);
let bp = infix_power(op);
// ...
}And define a new binding power for prefix operators.
The minus operator should have the highest power
for now, let’s set it to 30.
fn prefix_power(token: &Token) -> BindingPower {
match token {
Token::Sub => BindingPower(30),
_ => panic!("unsupported prefix binding power for {:?}", token),
}
}
// ...
fn prefix(tokenizer: &mut Tokenizer) -> Expr {
// ...
Some(Token::Sub) => {
let expr = expr(tokenizer, prefix_power(&Token::Sub));
Expr::Minus(Box::new(expr))
}
// ...
}The tests should pass.
running 8 tests
test test::binary_add_mul ... ok
test test::binary_add ... ok
test test::binary_mul ... ok
test test::binary_mul_add ... ok
test test::binary_sub ... ok
test test::literal ... ok
test test::prefix_minus_mul ... ok
test test::prefix_minus ... ok
test result: ok. 8 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.02sParentheses expression
Let’s go with the final one: Parentheses expressions having the form
( <inner> ), i.e. (1 + 2).
enum Expr {
// ...
Paren(Box<Expr>),
}
impl fmt::Display for Expr {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
match self {
// ...
Expr::Paren(expr) => write!(f, "({expr})"),
}
}
}
fn eval(expr: &Expr) -> i64 {
match expr {
// ...
Expr::Paren(expr) => eval(expr),
}
}Next, we define binding powers for its operators. There are some observations:
(is a prefix operator. It should have the lowest prefix binding power so that the inner expression is always parsed first.)acts as a parsing breaker, it must have the lowest infix binding power, so thatexprknows to stop parsing when exiting a parentheses context.
fn prefix_power(token: &Token) -> BindingPower {
match token {
Token::Sub => BindingPower(30),
Token::LParen => BindingPower(1),
_ => panic!("unsupported prefix binding power for {:?}", token),
}
}
fn infix_power(token: &Token) -> BindingPower {
match token {
Token::Add | Token::Sub => BindingPower(10),
Token::Mul => BindingPower(20),
Token::RParen => BindingPower(1),
_ => panic!("unsupported infix binding power for {:?}", token),
}
}Similar to the minus expression, this is defined
inside prefix. After getting the inner expression using expr,
we must also consume the ) token.
fn prefix(tokenizer: &mut Tokenizer) -> Expr {
match tokenizer.next() {
// ...
Some(Token::LParen) => {
let expr = expr(tokenizer, prefix_power(&Token::LParen));
let expr = Expr::Paren(Box::new(expr));
let Some(Token::RParen) = tokenizer.next() else {
panic!("expect Token::RParen");
};
expr
}
token => panic!("bad token {:?}", token),
}
}New testcases, and they all pass.
#[test]
fn paren() {
test_parse("(2)", "(2)", 2)
}
#[test]
fn paren_complex() {
test_parse("2 * (3 + 4) - (5 + 6)", "(- (* 2 ((+ 3 4))) ((+ 5 6)))", 3)
}
#[test]
fn paren_nested() {
test_parse(
"2 * (3 + 4 * ((5 + 6)))",
"(* 2 ((+ 3 (* 4 (((+ 5 6)))))))",
94,
)
}running 11 tests
test test::paren ... ok
test test::literal ... ok
test test::paren_complex ... ok
test test::binary_sub ... ok
test test::binary_mul_add ... ok
test test::binary_add_mul ... ok
test test::prefix_minus ... ok
test test::binary_add ... ok
test test::binary_mul ... ok
test test::prefix_minus_mul ... ok
test test::paren_nested ... ok
test result: ok. 11 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00sConclusion
We have our TDOP parser implemented. Using the same idea,
we can add more expressions,
i.e. divide expression (8 / 2), power expression (5 ^ 2), etc.
The TDOP parser, at first glance, might seem to be complicated (I still don’t fully understand its original paper). However, once we grasp the idea, it is elegant, easy to implement, and quite performant.
Most of the ideas in this post come from the very well-written tutorials from this index post. I had a very fun time playing with this algorithm, all the code can be found in my repo.